
Generating enough and diverse data through augmentation offers an efficient solution to the time-consuming and labor-intensive process of collecting and annotating pixel-wise images. Traditional data augmentation techniques often face challenges in manipulating high-level semantic attributes, such as materials and textures. In contrast, diffusion models offer a robust alternative, by effectively utilizing text-to-image or image-to-image transformation. However, existing diffusion-based methods are either computationally expensive or compromise on performance. To address this issue, we introduce a novel training-free pipeline that integrates pre-trained ControlNet and Vision-Language Models (VLMs) to generate synthetic images paired with pixel-level labels. This approach eliminates the need for manual annotations and significantly improves downstream tasks. To improve the fidelity and diversity, we add a Multi-way Prompt Generator, Mask Generator and High-quality Image Selection module. Our results on PASCAL-5i and COCO-20i present promising performance and outperform concurrent work for one-shot se- mantic segmentation.
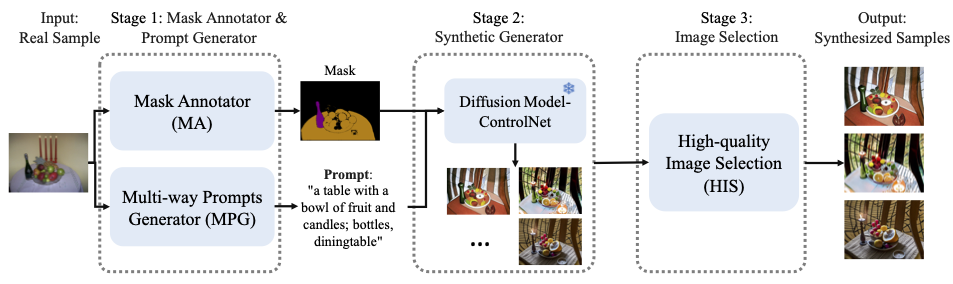
We generate diverse data with pixel-level labels without training.
DA-VLM improves One-shot Learning.

@article{ye2025data,
author = {Ye, Jiaojiao and Zhong, Jiaxing and Xie, Qian and Zhou, Yuzhou and Trigoni, Niki and Markham, Andrew},
title = {DA-VLM: Data Factory with Minimal Effort Using VLMs},
journal = {arXiv preprint arXiv:2510.05722},
year = {2025},
}